With this article, I would like to start a series on “Writing optimal and effective code in Erlang”. These articles are describing my point of view on the topic according to my experience in real world software development. I have been inspired by the marvelous book of M. Fowler and Co “Refactoring” if you haven’t read it yet – you definitely should do that. Put it on the top of your reading list, right after my article. In that book, authors describe a number of methods to simplify and optimize Object Oriented Code. Of course, if you have wide experience most methods would be obvious, but I have started to think: why don’t we have something similar in Functional Programming in application to Erlang?
And here we are, in the first article I describe some insights on Code Structural Pattern in Erlang which bring fast development and help to create effective code.
Code Structural Pattern in Erlang
Code Structural Pattern – is a general reusable solution to a commonly occurring situation/entity (don’t mix with OOP entity), here within a given context in code structure. It’s not necessary a process or behavior implementation, but it can be recognized as a repeated pieces of code. Don’t mix with Design Patterns from OOP, since we don’t have objects in Erlang. The main rule is – one general structural pattern = one erl module. Using correct naming for different structural patterns makes your program easy to understand for other people and you. I single out 6 main Structural Patterns in Erlang.
I. Application
Main module, which implements application behavior. This code starts execution at callback start/2 on call application:start or when your project is included into some other program app.src.
It’s a root of your program – starts top Supervisor and often do some useful init stuff:
case your_top_sup:start_link() of
{ok, _} = Res ->
ok = metrics_mngr:init(),
ok = http_handler_mngr:init(),
Res;
Error->
log:err(Error),
Error
end.
As it is the main entry point in your program and since it runs only once: it’s the perfect place to initialize external dependencies, run processes with global config and those which relies on it, like node discovery and joining a cluster.
II. OTP process
OTP processes are very important. It is an extension of specific part Erlang defined a generic process with your business logic. They can be gen_server, gen_fsm, gen_statem and gen_event. Each process type describes its own behavior. Refer to an erlang documentation to know more about it, this is out of the scope of this article.
OTP processes as a separate module should be used in several cases:
- you need a long living process (f.g. daemon, a job with periodic timer);
- your process is not so long living, but need to keep data in its state (f.e. connected client with client data saved in process state);
- your process handles different messages (f.e. driver to a database, which gets different message types from and to it).
OTP process is well known to every Erlang programmer and if you preferring to use it your programs are easier to understand. Try to limit the use of non-otp processes. Left it for short living tasks only, like processing something in parallel.
III. Supervisor
A supervisor is a special process from OTP scope but here I single it as the separate structural pattern. It is such OTP process which can start various OTP processes itself. The main function is to supervise started processes. It is an important part of Erlang process tree. If child process has crashed – supervisor will take actions, which were set up in its policy on start up. Supervisors can be dynamic and static. Static supervisors are one_for_one, one_for_all and rest_for_one. They start all specified children just after themselves. Not like dynamic, which start different specified processes: one process per child.
A dynamic supervisor is simple_one_for_one – it doesn’t start any children when started and can have only one type of child in spec. But it can spawn multiple processes per specification. Supervisor tree reflects the architecture of your project – other people will analyze it starting from the top supervisor and going down to its children. You should keep your tree simple as possible. Avoid dynamically adding children to static supervisors, as it adds complexity to understanding. Static supervisors are often used to start long-running background jobs, daemons, and other supervisors, while dynamic supervisors used for creating pools.
IV. Interface
The interface module, like the application, doesn’t have its own process. It just describes common behavior with callbacks, any other module can implement it. The Interface doesn’t contain any other code besides callbacks definitions and calling implementations:
-callback handle_common_stuff(Args :: type()) → Return :: type(). handle_common_stuff(Module, Args)-> Module:handle_common_stuff(Args).
It is better to move interfaces and their implementations to a separate directory. Then program becomes more clear – you can easily see all the implementations.
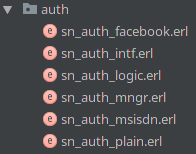
Here sn_auth_intrf.erl is an interface module and sn_auth_facebook.erl, sn_auth_msisdn.erl and sn_auth_plain.erl are it’s implementations.
V. Manager
Manager pattern is also just a module with a code. It contains API for part of program logic, it is responsible for. You can separate your logically tied code into another directory and treat it like a small library. Manager module is playing a role of an API and all other code will be just internal for the outside scope. In the other words: to ask any department to do something you have to ask this department manager first, and he will call suitable worker for you.
Using managers make your code more organized. It will also help you to easily move logically connected code into a separate library if you decide to divide your codebase later.
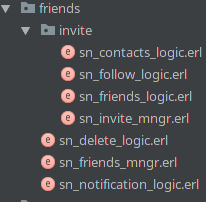
On this picture, you can see a piece of social network’s code, responsible for friendship and friends related stuff. This code is separated to its own directory, as there are lots of other modules. When entering this directory first you should notice its manager module. It will tell you which API is exposed outside. So, as in real live everything is simple: if you are in the unknown department, just ask its manager what this department is responsible for.
Old and bulky way to separate logically tied code was to only add a prefix into module name without dividing it into separate directories, it’s like if in open space all teams and managers are mixed together and not clear who is working together with whom. And if you are a newcomer you have to find and ask each manager which department he belongs to and what they responsible for. What is clearly not the most productive way of working.
Here you can see sn_delete_logic – it contains all code, which describes deleting friends. Its exports shouldn’t be used outside this package. For external usages, they are reexported throug sn_friends_mngr – manager of this “department”. sn_notification_logic contains all rules about notification friends and sending events to them. It’s exported functions are also included to sn_friends_mngr, as a part of API.
Invitation logic is more complex, so it is moved to another subpackage, with its own manager – sn_invite_mngr. In this situation, all calls from friends to invitation package’s functions should be done through sn_invite_mngr.
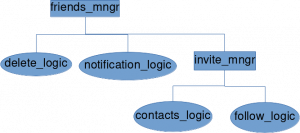
A manager always exposes other module’s exports, or down level manager’s exports. You can see same code represented as a tree.
VI. Logic
The logic module looks just opposite to the manager one. It contains all internal code, which can be used only inside the package where the logic module exists. It can’t be used either up nor down in subpackages.
Use manager to expose current logic module functions to the rest of a program. Like you saw in the previous example: there are 2 logic modules in invitation subpackage. They display the exact program logic – user can become friends via the mutual following (is described in sn_follow_logic) or if their phone numbers mutually exist in their address books (is described in sn_contacts_logic).
By separating your code this way you make testing it much easier:
- no need to export internal functions especially for calling in tests if they are already exported for a manager;
- exported in logic modules functions can be easily mocked.
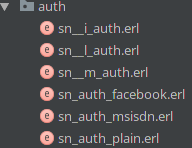
The second way to use logic modules is to store internal common code, which is in use by multiple modules of the same package. What reduces code duplication dramatically. Here you can see an auth package with three implementations, responsible for authentication via Facebook, SMS and plain passwords. They have their own codebase but also use sn_auth_logic common functions for doing common staff such as checking credentials, passing log_in and log_out events and some others.
Separating code this way helps you to change tool specific code without changing business logic.
Naming Convention
Now when we got a brief understanding of main Code Structural Patterns, let us take a closer look at naming convention.
There are two ways entity modules can be named: suffix and prefix. Doesn’t matter which one will seem to be more convenient to you or your team – you just need to be consistent.
Suffix naming is default to Erlang, you can see _app and _sup suffixes in nearly every application. Interface modules will get _intf suffix, managers – _mngr, logic – _logic. OTP process modules don’t have a special suffix, although they stand out because of that.
This way has some cons:
- it is too bulky;
- you should read the whole name to determine the type;
- entities don’t stand out of other code.
There is another way of naming modules – prefix naming.
In this case, modules get this prefixes at name. So, names are compact and can be easily seen among other modules. They are also always on top when sorting names alphabetically. Check follow table to compare on 2 ways of naming convention. Where foo symbolizes a namespace:
| Type | Prefix | Pref Example | Suffix | Suf Example |
| Application | __a | foo__a_social_net | _app | foo_social_net_app |
| Supervisor | __s | foo__s_top | _sup | foo_top_sup |
| Interface | __i | foo__i_handler | _intf | foo_handler_intf |
| Manager | __m | foo__m_friends | _mngr | foo_friends_mngr |
| Logic | __l | foo__l_export | _logic | foo_export_logic |
As a short conclusion, I hope by reading this article you got a general understanding of Code Structural Pattern in Erlang and will implement it in practice. My bits of advice would be:
- Don’t throw all erl modules into one src directory, like into a rubbish bin – divide logically tight code into separate sub-directories;
- Use structural code patterns, inside sub-directories introduce:
- Manager as API holder for external use;
- Interface for internal general callbacks;
- Logic modules as code implementation for shared or logic for managers calls;
- Apply correct and consistent naming convention.
As you can see – using this technique makes your code more ordered, better testing and easy to understand and modify.
For arguing and/or asking questions welcome to comments behind. Full sample project code can be found in git.
Have a nice day :).