I would like to introduce a new tool for end-to-end testing – Catcher.
What is an e2e test?
End-to-end test usually answers the questions like: “Was this user really created, or service just returned 200 without any action?”.
In comparison with project level tests (unit/functional/integration) e2e runs against the whole system. They can call your backend’s http endpoints, check values written to the database, message queue, ask another services about changes and even emulate external service behaviour.
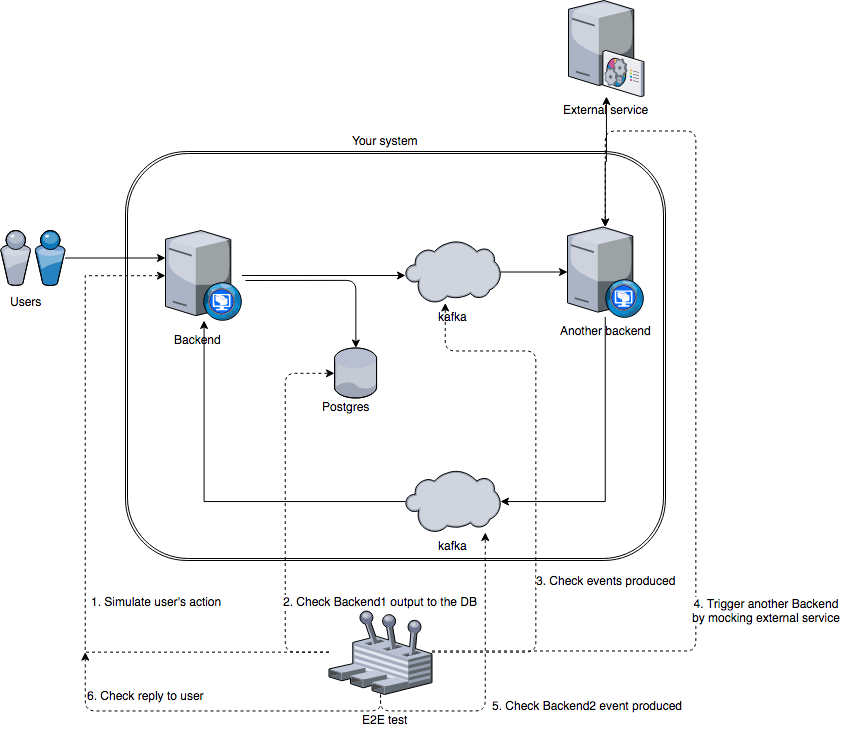
E2E tests are the tests with the highest level. They are usually intended to verify that a system meets the requirements and all components can interact with each other.
Why do we need e2e tests?
Why do we need to write these tests? Even M.Fowler recommends to avoid these tests in a favor of more simple ones.
However, on more higher abstract layer tests are written – the less rewrites will be done. In case of refactoring, unit tests are usually rewritten completely. You should also spend most of your time on functional tests during code changes. But end-to-end tests should check your business logic, which is unlikely to change very often.
Besides that, even the full coverage of all microservices doesn’t guarantee their correct in-between interaction. Developers may incorrectly implement the protocol (naming or data type errors). Or develop new features relying on the data schema from the documentation. Anyway you can get a surprise at the prod environment, since schema mismatches: a mess in the data or someone forgot to update the schema.
And each service’s tests would be green.
Why do we need to automate tests?
Indeed. In my previous company was decided not to spend efforts on setting up automated tests, because it takes time. Our system wasn’t big at that time (10-15 microservices with common Kafka). CTO said that “tests are not important, the main thing is – system should work”. So we were doing manual tests on multiple environments.
How it looked like:
- Discuss with owners of other microservices what should be deployed to test a new feature.
- Deploy all services.
- Connect to remote kafka (double ssh via gateway).
- Connect to k8s logs.
- Manually form and send kafka message (thanks god it was plain json).
- Check the logs in attempt to understand whether it worked or not.
And now let’s add a fly in this ointment: majority of tests requires fresh users to be created, because it was difficult to reuse existing one.
How user sign up looked like:
- Insert various data (name, email, etc).
- Insert personal data (address, phone, various tax data).
- Insert bank data.
- Answer 20-40 questions.
- Pass IdNow (there was mock up for dev, but stage took 5+ minutes, because their sandbox was sometimes overloaded).
- This step requires opening bank account which you can’t do via front-end. You have to go to kafka via ssh and act as a mock-service (send a message, that account was opened).
- Go to moderator’s account on another frontend and approve the user you’ve just created.
Super, the user has just been created! Now lets add another fly: some tests require more than one user. When tests fail you have to start again with registering users.
How new features pass business team’s checks? The same actions need to be done in the next environment.
After some time you start feeling yourself like a monkey, clicking these numerous buttons, registering users and performing manual steps. Also, some developers had problems with kafka connection or didn’t know about tmux and faced this bug with default terminal and 80 char limit.
Pros:
- No need to do a set up. Just test on existing environment.
- Don’t need high qualification. Can be done by cheap specialists
Cons:
- Takes much time (the further – the more).
- Usually only new features are tested (without ensuring, that all features, tested previously are ok).
- Usually manual testing is performed by qualified developers (expensive developers are utilized on cheap job).
How to automate?
If you’ve read till this point and are still sure, that manual testing is ok and everything was done right in this company, then the other part of my article won’t be interesting to you.
Developers can have two ways to automate repeating actions. They depend on the type of the programmer, who had enough time:
- Standalone back-end service, which lives in your environment. Tests are hardcoded inside and are triggered via endpoints. May be partly automated with CI.
- Script with hardcoded test. It differs only in way of run. You need to connect somewhere (probably via ssh) and call this script. Can be put into a Docker image. May be also automated with CI.
Sounds good. Any problems?
Yes. Such tests are usually created using technologies that the author knows. Usually it is a scripting language such as python or ruby, which allows you to write a test quickly and easily.
However, sometimes you can stumble upon a bunch of bash scripts, C or something more exotic. Once I spent a week rewriting the bike on bash scripts to a python, because these scripts were no longer extensible and no one really knew how do they work or what do they test . The example of self-made end-to-end test is here.
Pros:
- They are automated!
Cons:
- Has additional requirements to developer’s qualification (F.e. main language is Java, but tests were written in Python)
- You write a code to test a code (who will test the tests?)
Is there anything out of the box?
Of course. Just look on BDD. There is Cucumber or Gauge.
In short – the developer describes the business scenario in a special language and writes the implementation later. This language is usually human readable. It is assumed that it will be read/written not only by developers, but also by project managers.
Together with implementation scenario is stored in the standalone project and is run by third party services (Cucumber, Gauge…).
The scenario:
Customer sign-up ================ * Go to sign up page Customer sign-up ---------------- tags: sign-up, customer * Sign up a new customer with name "John" email "jdoe@test.de" and "password" * Check if the sign up was successful
The implementation:
@Step("Sign up as <customer> with email <test@example.com> and <password>")
public void signUp(String customer, String email, String password) {
WebDriver webDriver = Driver.webDriver;
WebElement form = webDriver.findElement(By.id("new_user"));
form.findElement(By.name("user[username]")).sendKeys(customer);
form.findElement(By.name("user[email]")).sendKeys(email);
form.findElement(By.name("user[password]")).sendKeys(password);
form.findElement(By.name("user[password_confirmation]")).sendKeys(password);
form.findElement(By.name("commit")).click();
}
@Step("Check if the sign up was successful")
public void checkSignUpSuccessful() {
WebDriver webDriver = Driver.webDriver;
WebElement message = webDriver.findElements(By.className("message"));
assertThat(message.getText(), is("You have been signed up successfully!"));
}
The full project can be found here.
Pros:
- Business logic is described in human readable language and is stored in one place (can be used as documentation).
- Existing solutions are used. Developers only need to know how to use them.
Cons:
- Managers won’t read/write these specs.
- You have to maintain both specifications and implementations.
Why do we need Catcher?
Of course, to simplify the process.
The developer just writes a test scenarios in json or yaml, catcher executes them. The scenario is just a set of consecutive steps, f.e.:
steps:
- http:
post:
url: '127.0.0.1/save_data'
body: {key: '1', data: 'foo'}
- postgres:
request:
conf: 'dbname=test user=test host=localhost password=test'
query: 'select * from test where id=1'
Catcher supports Jinja2 templates, so you can use variables instead of hardcoded values. You can also store global variables in inventory files (as in ansible), fetch them from environment or register new one.
variables:
bonus: 5000
initial_value: 1000
steps:
- http:
post:
url: '{{ user_service }}/sign_up'
body: {username: 'test_user_{{ RANDOM_INT }}', data: 'stub'}
register: {user_id: '{{ OUTPUT.uuid }}'
- kafka:
consume:
server: '{{ kafka }}'
topic: '{{ new_users_topic }}'
where:
equals: {the: '{{ MESSAGE.uuid }}', is: '{{ user_id }}'}
register: {balance: '{{ OUTPUT.initial_balance }}'}
Additionally, you can run verification steps:
- check: # check user’s initial balance
equals: {the: '{{ balance }}', is: '{{ initial_value + bonus }}'}
You can also run one tests from another, which allows you to reuse the code and keep it separated logically.
include:
file: register_user.yaml
as: sign_up
steps:
# .... some steps
- run:
include: sign_up
# .... some steps
Catcher also has a tag system – you can run only some special steps from included test.
Besides built-in steps and additional repository it is possible to write your own modules on python (simply by inheriting ExternalStep) or in any other language:
#!/bin/bash
one=$(echo ${1} | jq -r '.add.the')
two=$(echo ${1} | jq -r '.add.to')
echo $((${one} + ${two}))
And executing it:
---
variables:
one: 1
two: 2
steps:
- math:
add: {the: '{{ one }}', to: '{{ two }}'}
register: {sum: '{{ OUTPUT }}'}
It is recommended to place tests in the docker and run them via CI.
Docker image can also be used in Marathon / K8s to test an existing environment. At the moment I am working on a backend (analogue of AnsibleTower) to make the testing process even easier and more convenient.
The example of e2e test for a group of microservices is here.
Working example of e2e test with Travis integration is here.
Pros:
- No need to write any code (only in case of custom modules).
- Switching environments via inventory files (like in ansible).
- Easy extendable with custom modules (in any language).
- Ready to use modules.
Cons:
- The developer have to know not very human readable DSL (in comparison with other BDD tools).
Instead of conclusion
You can use standard technologies or write something on your own. But I am talking about microservices here. They are characterized by a wide variety of technologies and a big number of teams. If for JVM team junit + testcontainers will be an excellent choice, Erlang team will select common test. After your department will grow, all e2e tests will be given to a dedicated team – infrastructure or qa. Imagine how happy they will be because of this zoo?
When I was writing this tool, I just wanted to reduce the time I usually spend on tests. In every new company I usually have to write (or rewrite) such test system.
However, this tool turned out to be more flexible than I’ve expected. F.e. Catcher can also be used for organizing centralized migrations and updating microservice systems, or data pipelines integration testing.